Séria "Classification Tree" obsahuje:
Classification Tree: 2D Problém
Definícia problému:
Máme n skupín dát, kde n je neznáme číslo. Použitím SVM algoritmu chceme postupne nájsť koeficienty všetkých sepáratov oddeľujúcich tieto skupiny. Počet všetkých separátov je (n-1). Nájdené koeficienty je ďalej potrebné uložiť do vhodnej dátovej štruktúry, aby sme ich mohli neskôr využiť v kroku klasifikácie.
Riešenie problému:
Aby sme nemuseli každý separátor hľadať manuálne, ako to bolo v predošlom príklade, na vyriešenie problému použijeme funkciu vytvorenú v Matlabe.
Funkcia create___nodes nájde koeficienty všetkých separátorov opakovaným volaním funkcie yalmip_SVM, ktorú som uverejnila v príspevku Yalmip & SVM: Universal Function, pomocou for slučiek.
Prvým vstupným parametrom do funkcie je premenná train_struct, ktorá je typu struct array a obsahuje polia name a data. V poli name sa nachádzajú mená jednotlivých skupín dát a v poli data tréningové matice. Premenná je rozmeru 1xn, kde n je počet všetkých skupín. Význam druhého vstupného parametru gamma je vysvetlený v článku Yalmip & SVM: Universal Function.
Ako sa pracuje s premennou typu struct array nájdeme napr. na stránke MathWorks.
function output = create_nodes(train_struct, gamma)n = length(train_struct);output = [];for i = 1:(n-1) train_class1 = train_struct(i).data; train_class2 = []; for j = (i+1):n train_rest = train_struct(j).data; train_class2 = [train_class2, train_rest]; end [a_opt, b_opt] = yalmip_SVM(train_class1, train_class2, gamma); node = []; node.a = a_opt; node.b = b_opt; node.left = train_struct(i).name; if (i == (n-1)) node.right = train_struct(end).name; else node.right = []; end output = [output, node];endendVýstupom z funkcie je premenná output, tiež typu struct array rozmeru 1x(n-1). Táto premenná predstavuje náš klasifikačný strom zložený z jednotlivých uzlov. Pre 4 skupiny dát by takýto strom vyzeral nasledovne. (Môj algoritmus vytvára stromy, ktoré sa vždy ďalej vetvia smerom doprava.)
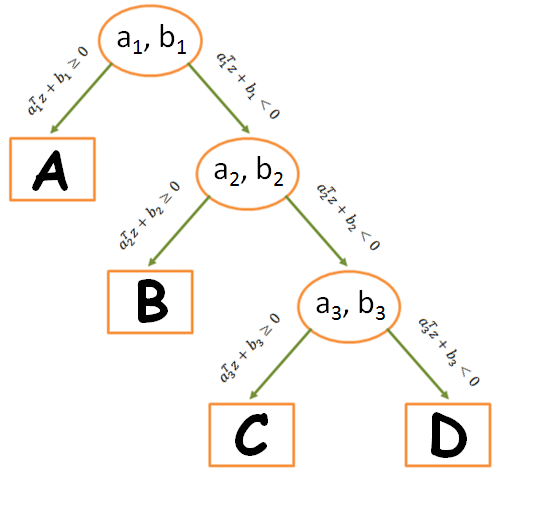
Premenná output obsahuje polia a, b, right a left. Oválnym uzlom postupne vypĺňame všetky tieto polia. Do polí a a b sa po jednotlivých iteráciach zapisujú hodnoty koeficientov separátorov. Polia left a right obsahujú informácie o dcérskych uzloch. Z obrázka vyplýva, že pole left bude vždy obsahovať názov skupiny. Do poľa right sa môže zapísať názov poslednej skupiny alebo podradený oválny uzol. Z rozmeru premennej vyplýva, že obsahuje iba oválne uzly. Kedže takéto uzly v sebe majú informáciu o pravej aj ľavej strane, je to postačujúce.