There is a room. Is there someone or is the room empty? We cannot see, surveillance cameras, video records are not allowed. But what we can do is that we are able to measure current temperature, humidity, light and CO2 in the room. If there is a dependency between the measured variables and the room occupancy, it might be possible to determine whether are any people there. To do that we need the machine learning tools and the data, from which an algorithm can learn.
It’s time to show that previously mentioned classifiers, which I was analyzing in my project, can be useful in another way. Needed experimental data are available here. This dataset is much larger compared to the previous wine dataset, it contains 20557 observations. They were already divided into the training set and two testing sets, but testing observations was undesirable too many. To pick around 75 % from all of them as the training data is a good choice, so I will use 15557 observations to train the models and the rest 5000 as the testing data, which will be used to predict the results of unlabeled observations to evaluate reliability of the model. Each observation has a label 1 or 0, whether the room is occupied or not, and next 5 attributes according to which must be decided.
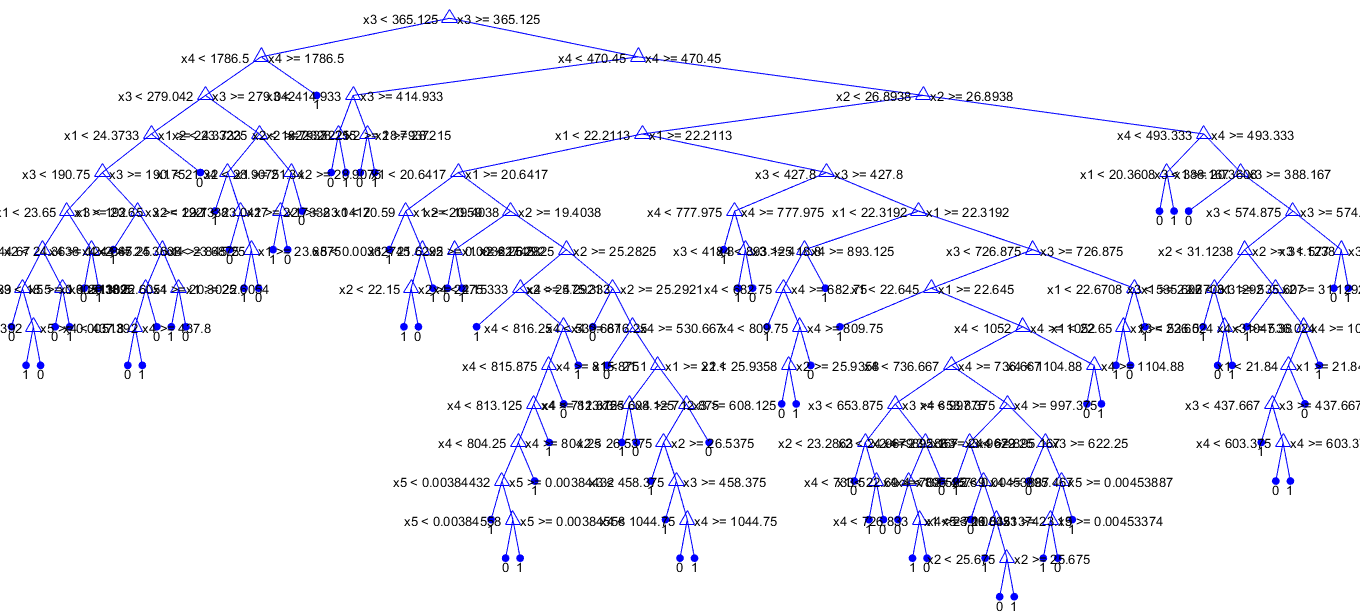
Again, I started with the classification trees. The bigger training set is, the more complicated the tree became as can be seen above. From 5000 testing samples 122 have been classified wrong, with optimized hyperparameter only 113 of them, but with optimizing all hyperparameters 182 samples were classified incorrectly. This still makes little sense to me, when a purpose of that function is an improvement, at least it should not get worse. Next 4 classifiers were examined in the same way. The occupancy dataset differs from the wine dataset in number of classes, this time we are dealing with a binary classification. So, instead of the multiclass-SVM method (ECOC) easily could be used the ordinary support vector machine model and its function fitcsvm.
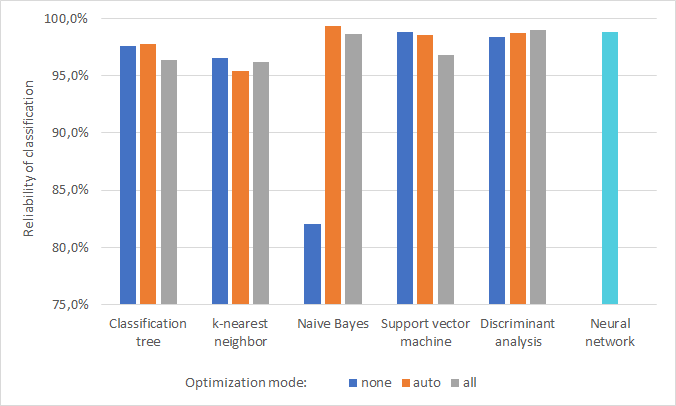
With 99.3 % certainty, the naive Bayes model can predict whether is someone in the room. That’s pretty accurate. Other classifiers also act quite well. Each of them can be used for solving similar problems, maybe with one exception. Waiting for the optimized SVM model definitely doesn’t worth it, unlike the naive Bayes classifier that significantly improve its performance when is optimized. Results for all classifiers can be found in the tables below.
In addition to machine learning classifiers we can use a neural network as well. The neural network can be easily created in MATLAB in less than 2 seconds, evaluation of testing samples took up to 80 seconds. When is the network trained again, parameters are fitted differently even though the training data are the same. Therefore, each time the number of incorrectly classified samples varies from 35 to 180 (from 5000).
| Mode | Clasification tree | k-nearest neighbors | Naive Bayes | Support vector machine | Discriminant analysis |
| without optimization | 122 | 174 | 896 | 59 | 81 |
| ‘auto’ optimization | 113 | 230 | 34 | 71 | 64 |
| ‘all’ optimization | 182 | 193 | 68 | 159 | 53 |
| Mode | Clasification tree | k-nearest neighbors | Naive Bayes | Support vector machine | Discriminant analysis |
| without optimization | 97.6 % | 96.5 % | 82.1 % | 98.8 % | 98.4 % |
| ‘auto’ optimization | 97.7 % | 95.4 % | 99.3 % | 98.6 % | 98.7 % |
| ‘all’ optimization | 96.4 % | 96.1 % | 98.6 % | 96.8 % | 98.9 % |
| Mode | Clasification tree | k-nearest neighbors | Naive Bayes | Support vector machine | Discriminant analysis |
| without optimization | 0.10 s | 0.08 s | 0.07 s | 4.36 s | 0.08 s |
| ‘auto’ optimization | 79.5 s | 321.9 s | 632.1 s | 9 528.3 s | 46.2 s |
| ‘all’ optimization | 71.2 s | 270.2 s | 418.1 s | 10 321.9 s | 76.7 s |