For the Semester Project II, I worked on model identification of a propylene polymerisation reactor using physics-informed neural networks (PINNs). The project consisted of two main parts – mathematical modelling of a fluidized bed reactor and training neural networks on data generated from the models of a polypropylene reactor.
Why Polypropylene?
Polypropylene is one of the most widely used plastics in the world, accounting for more than 25% of global polymer demand. It has the lowest density among commodity plastics, is cheap and strong, and offers excellent resistance to moisture and chemicals. High demand and a competitive industrial environment call for precise process models, making this the field where modern machine learning approaches, including PINNs, can come into play.
Modelling of a Fluidized Bed Reactor
In industry, polypropylene is commonly produced in fluidized bed reactors (FBR), where gaseous propylene monomer, mixed with hydrogen and nitrogen, fluidizes a bed of catalyst and polymer particles. To ensure that the produced polypropylene (PP) forms isotactic chains, essential for achieving the desired material properties, the Ziegler-Natta catalyst with an appropriate co-catalyst is added to the reactor.
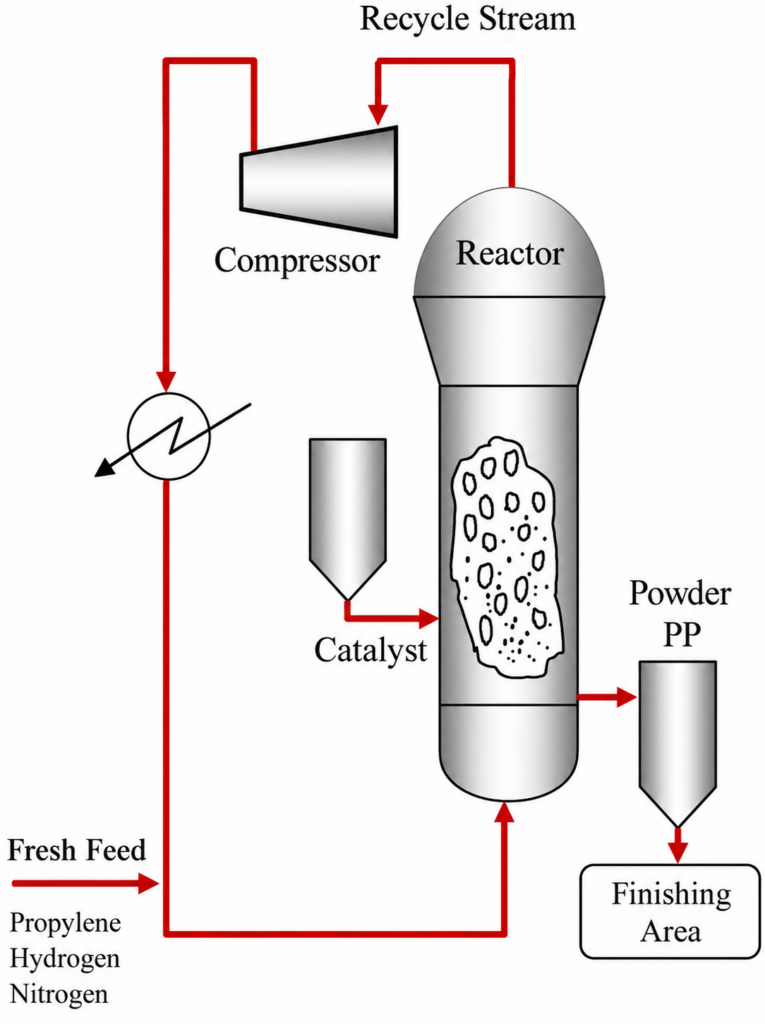
The polymerisation reaction is described by a complex mechanism, with the Ziegler-Natta catalyst usually assumed to have more than one active site. Multiple co-occurring factors can terminate polymer chain elongation at different lengths, resulting in a broad chain length distribution. To manage this, the FBR model can be simplified using the method of moments, which significantly reduces the number of differential equations while allowing polymer properties, such as the melt flow index (MFI) and polydispersity index (PDI), to be calculated directly.
Based on that and drawing on the previously published research of Shamiri and Atan, I have gradually implemented three models of increasing complexity in a Python environment:
- Well-mixed model (WMM) – the entire reactor as a single perfectly mixed phase;
- Constant bubble size model (CBSM) – a two-phase model with a bubble and an emulsion phase;
- Improved model – an improvement of CBSM with all three gaseous components entering the reactor, mass and heat transfer resistances dynamically calculated based on actual values of parameters, and rate constants being in Arrhenius form.
The first two models were allowed to reach a steady state from a starting operating point and after that a five percent step increase in the catalyst inlet flow occurred. As can be seen, the simpler model reached unrealistically high values of temperature, while the second one gave a physically more realistic description of the reactor, with space for further improvement due to the simplified assumptions.
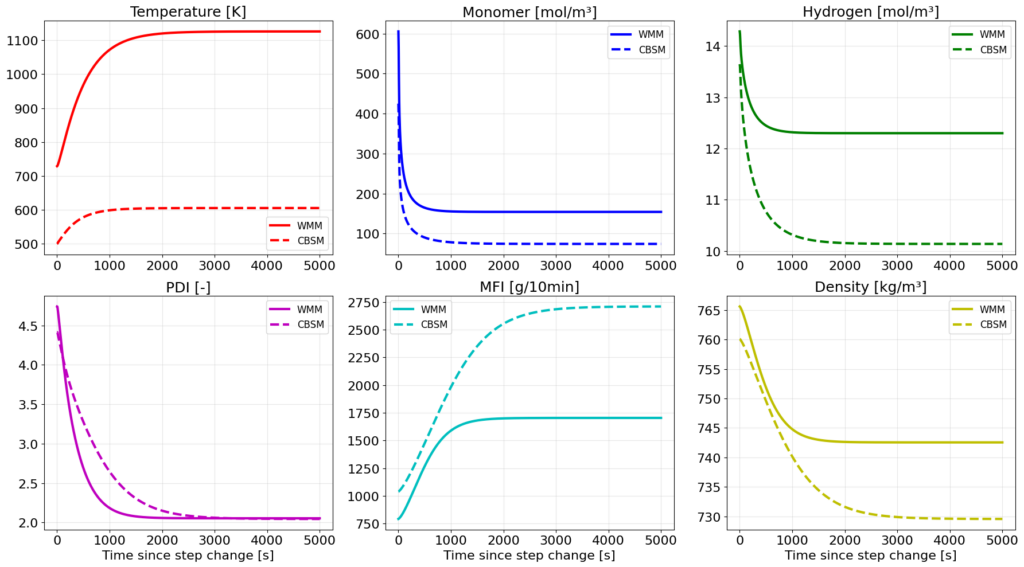
The last model, an improved CBSM giving more reasonable results, was then used to generate a noisy dataset with step changes of the inputs, reflecting a real industrial environment, which would later be used in the second part of the project for training PINNs.
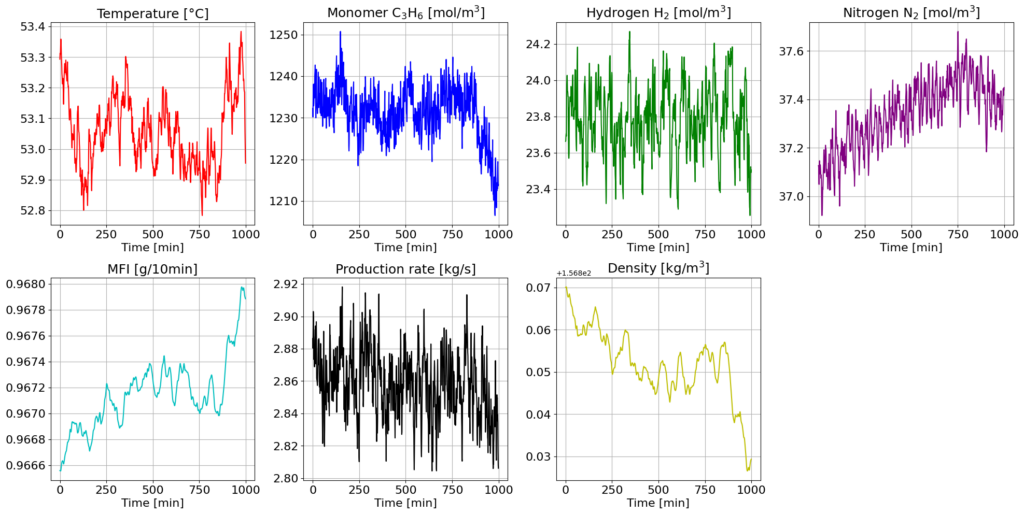
Neural Networks on a CSTR Model
In the second part of the semester project, I first trained several individual neural network (NN) architectures and tested their behaviour on a simpler model of a continuous stirred-tank reactor (CSTR), described by two differential equations – one for concentration of a reactant A and one for temperature.
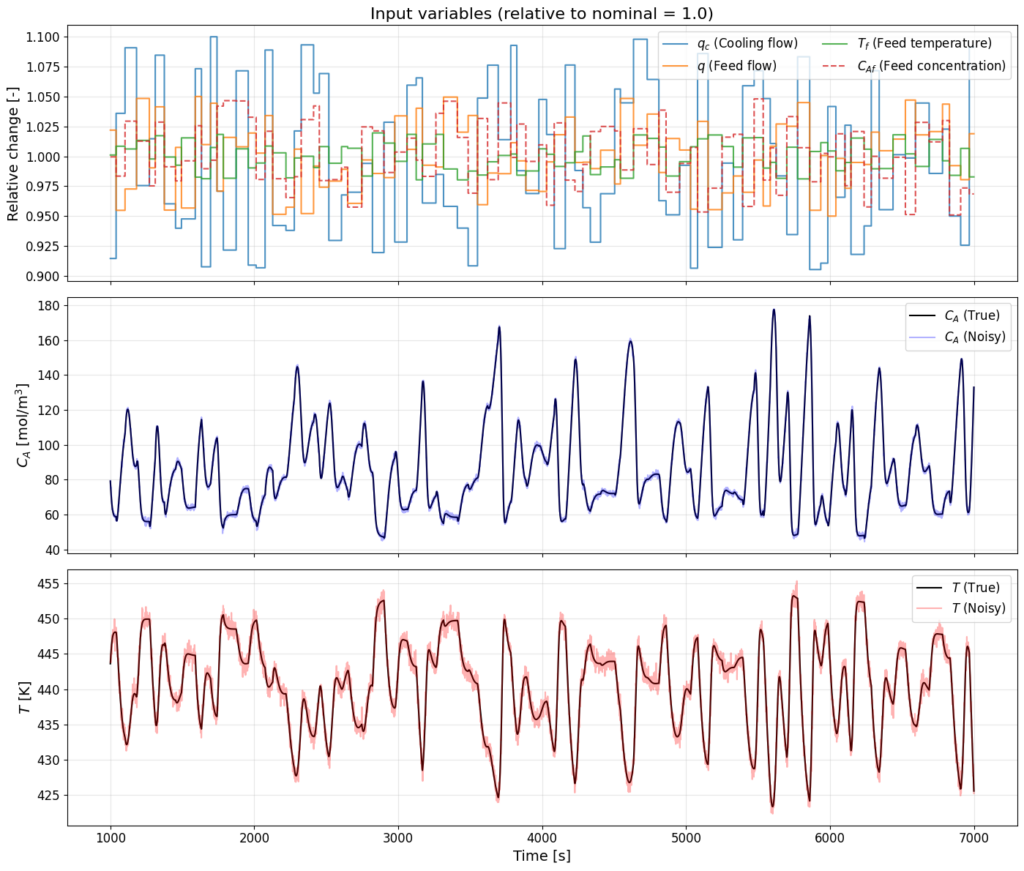
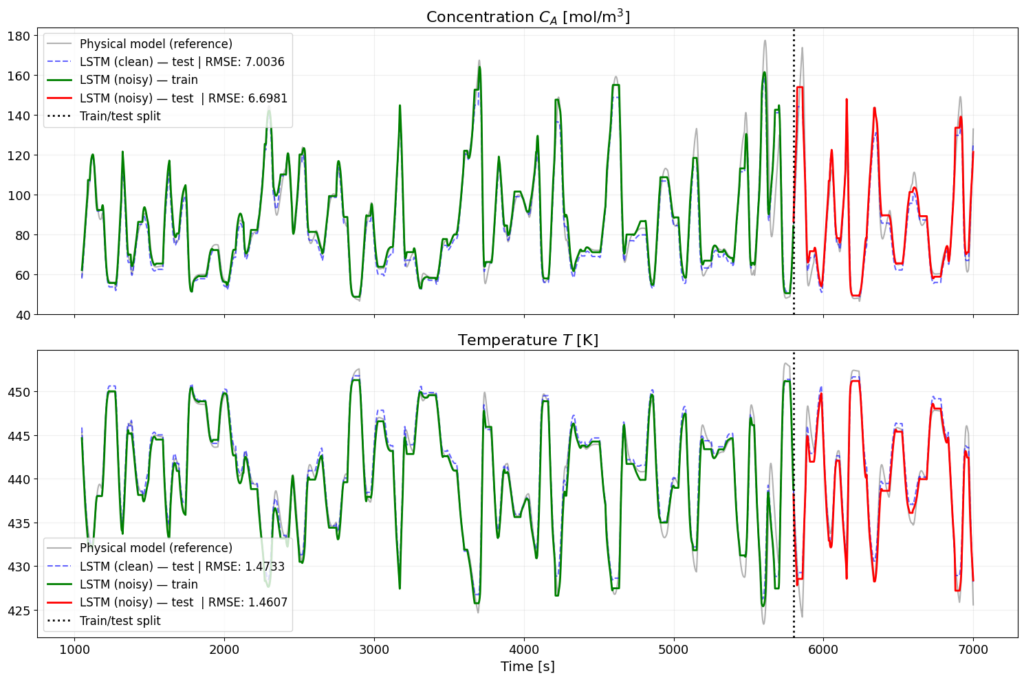
I compared four networks – two feedforward networks (FFNN), using a different number of CSTR inputs and hidden layers, a network with a GRU layer, and a network with an LSTM layer. While the simple feedforward networks produced overly flat predictions and failed to reach the peaks of the reference signal, the recurrent architectures with a look-back window of 50 time steps were able to follow the signal almost perfectly. The best results on noisy data were achieved by the LSTM network, with an RMSE of 6.70 for concentration and 1.46 for temperature.
Physics-Informed Neural Networks
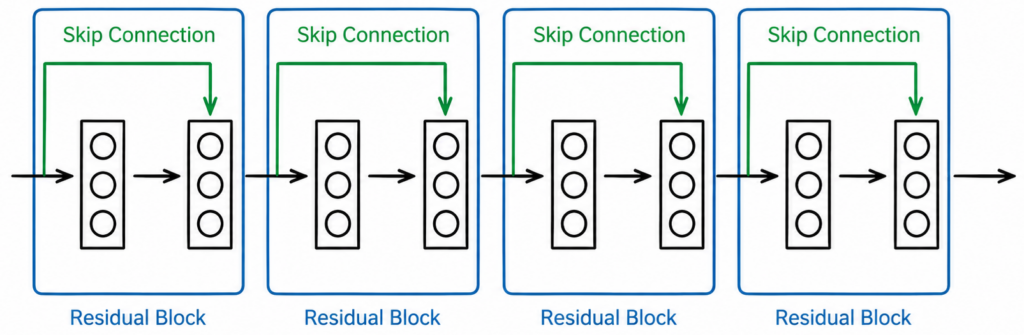
The main topic of the project was physics-informed neural networks, which add a physics loss to the training, penalising violations of the differential equations of the model. To improve the prediction of the tested feedforward networks, I have designed a PINN with four residual blocks. The PINN itself did not perform well on noisy data from the CSTR model, and additional Lasso regularisation did not bring a significant improvement either. The breakthrough came only after filtering the inputs with an exponential moving average (EMA), which reduced the RMSE for concentration from about 50 to 20 and for temperature from 15 to 4.8.
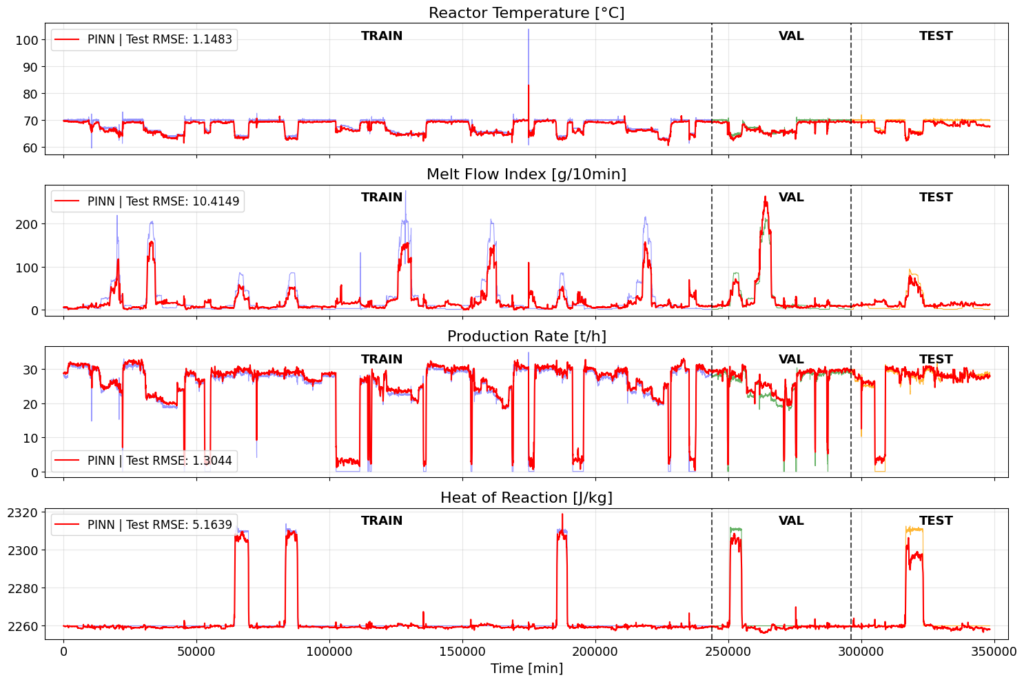
Finally, I have combined this designed feedforward PINN with the industrial-scale FBR model for physics loss and industrial data for data loss evaluation. The results are promising, but there is still much to improve.
Conclusion
This project gave me a solid foundation in polymerisation reactor modelling and a clear overview of various neural network architectures, from simple feedforward networks to PINNs. Moving forward, I plan to improve the PINN structure using LSTM layers to handle real industrial data, and ultimately design a controller based on the model for potential industrial applications.