Warning: this story has no happy ending. In the previous post I promised that we will grow better trees. For these kinds of problems optimization is used. In MATLAB, function fitctree which returns fitted classification tree can have an additional argument 'OptimizeHyperparameters' with value 'auto' or 'all' (and also 'none', but this is useless). The optimization attempts to minimize the cross-validation loss for fitctree by varying the parameters. Classification loss function measures the predictive inaccuracy of classification models, where lower loss indicates a better model. Value 'auto' uses only MinLeafSize as a parameter to optimize and value 'all' optimizes all available parameters (MinLeafSize, MaxNumSplits and SplitCriterion). During optimization function fitctree iterates 30 times over different values of a parameters and tries to find an optimal solution, where an objective function is the misclassification rate. The hyperparameter MaxNumSplits (Maximal number of decision splits) limits number of nodes, thus the lower value is, the lesser complex tree we get. With hyperparameter MinLeafSize (Minimum number of leaf node observations) we can also control a tree depth. Its value determines how many observations is needed to justify a split.
Ok, according to a theory there should be no problem, right? Because optimization costs time, I had to increase step from 1 % to 10 % and decrease number of iteration from 1000 to only 50 (if not, the program would be still running). Then I will compare reliability of trees created with and without optimization. After 14 hours (‘auto’ optimization lasted 5h 45m[1] and ‘all’ 8h 15m, in comparison ‘none’ took 5 seconds) while the program was running, I got this:
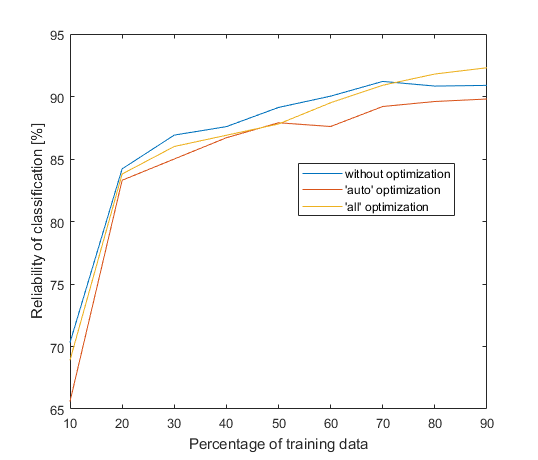

Look closely at the legend, that’s certainly not what we want. I am trying to find signs of mentioned intelligence, but this is pretty dumb. What’s wrong with you, MATLAB?! In the figure is still randomness, because average of 50 iterations is not enough, but we can see that classification without optimization wins in all cases except last 2 and one-parameter optimization ('auto') fails every time. I should admit that I didn’t sacrifice another 14 hours for verification, but I sacrificed 5 seconds for trees without optimization and there were few cases, where mode 'all' achieved slightly better results than mode without optimization. I still think this is far from good. Let’s compare reliability of classification when percentage of training data is 70 % and 80 % (it’s the most significant ratio):
| Mode | Time per one tree | Reliability at 70 % | Reliability at 80 % |
| without optimization | 0.01 s | 91.2 % | 90.8 % |
| ‘auto’ optimization | 46.3 s | 89.2 % | 89.6 % |
| ‘all’ optimization | 65.5 s | 90.9 % | 91.8 % |
Summed up, my computer spent more than 8 hours to gain 0.3 % worse result when percentage of training data was 70 %, but it takes so long because I needed a lot of trees. Time for one tree looks better. Results also look better if we compare reliability of classification when percentage of training data is set to 80 %. Then classification with all-parameter optimization is the winner. However, 1 % advantage is not very convincing and to be sure it is not just a coincidence I runned the program again (only for 80 % of training data). The results still didn’t persuade me about the benefits of optimization. Consider by yourself whether that time is worth tenths of a percent, but I’m not very satisfied.
Who’s to blame now? It seems that from options – dataset, computer, MATLAB, or me – I have the worst prospects, but I think this time I might be right, hope so. Or probably the size of the dataset is not appropriate for this optimization. Anyway, this was my first date with optimization (I “accidentally” missed an optimization course last year, same as everything else) and it didn’t end up very well. But I don’t give up, yet[2]. Nevertheless, some people see the glass as half full instead of half empty (a chemist sees glass entirely full – half is a liquid, half is a gas) and look only on the bright side of bad situation. These people could say that trees are wonderful, because they immediately classified samples with reliability higher than 90 %. Thus a little space left for improvement by optimization. After all, the happy end is not that far.

1. Actually, it was two times 5h 45m because I am so skillful and lost previous data (and last bits of my happiness disappeared with them). ↩
2. A depressing tone of this post is just an illusion, after all I found the results quite funny and mysterious. ↩